Reference
[Paper] [Code] Automatic Music Playlist Continuation via Neighbor-based Collaborative Filtering and Discriminative ReweightingReranking (RecSys’18 Challenge)
위의 논문을 바탕으로 Neighbor 모델을 만들었다.
Process
1. Notaion
- $\mathcal{P}$ : All Playlists in train.json
- $\mathcal{T}$ : All Tracks
- $u$ : Target Playlist in val.json or test.json
- $v$ : Candidate Playlist in train.json
- Known Track $j \in u$ (same as $j \in \mathcal{T}(u)$)
- Candidate Track $i \in v$
- $\mathcal{P}(i)$ : Playlists that contain track $i$
- $\mathcal{T}(u)$ : Tracks in playlist $u$
- $\mathbf{x}_i$ : Feature Vector for Candidate Track $i$
- $s_{ij}$ : Similarity between Candidate Track $i$ and Known Track $j$
- $r_{ui}$ : Relevance between Candidate Track $i$ and Target Playlist $u$
- $\alpha$, $\beta$ : Hyperparameters
2. Feature Vector $\mathbf{x}_i$
\[\scriptsize{ (\mathbf{x}_i)_{[v]} = \begin{cases} \cfrac{|\mathcal{T}(u) \cup \mathcal{T}(v) | }{|\mathcal{T}(v)|^\alpha} & \scriptsize{\text{if playlist $v$ contains track $i$}} \\ 0 & \scriptsize{\text{else}} \end{cases} }\]where $0 \le \alpha \le 1$ is a hyperparameter that controls the influence of long playlists.
길이가 긴 playlist일수록 더 많은 track을 포함하고 많은 target playlist와 연관성이 높게 나온다.
많은 target playlist와 연관성이 높은 playlist는 특정 target playlist의 특성을 대표한다고 보기 어렵기 때문에 playlist 길이로 나눠주어 길이가 긴 playlist의 효과를 감소시켰다.
$\alpha \rightarrow 0$일수록 playlist의 길이를 고려하지 않고 $\alpha \rightarrow 1$일수록 playlist의 길이를 많이 고려한다.
따라서 hyperparameter를 조절할 때 $0.5 \sim 1.0$ 사이의 값을 우선적으로 사용하였다.
feature vector $\mathbf{x}_i$는 하나의 target playlist $u$와 하나의 candidate track $i$에서 모든 playlist $v \in \mathcal{P}$에 대해 구하기 때문에 shape은 다음과 같다.
\[\scriptsize{ \mathbf{x}_i \in \mathbb{R}^{|\mathcal{P}|} }\]3. Similarity $s_{ij}$
\[\scriptsize{ s_{ij} = \cfrac{(\mathbf{x}_i)^T \mathbf{x}_j}{|\mathcal{P}(i)|^\beta |\mathcal{P}(j)|^{1-\beta}} }\]where $0 \le \beta \le 1$ is hyperparameter.
similarity는 feature vector $\mathbf{x}_i$와 $\mathbf{x}_j$를 내적해서 구한다.
유의할 점은 위의 식은 playlist-track similarity가 아니라 track-track similarity라는 것이다.
또한 track $i$를 포함하는 playlist 개수와 track $j$를 포함하는 playlist 개수로 나눠주는데 앞의 아이디어와 유사하다는 것을 알 수 있다.
많은 playlist에 들어있는 track은 특정 playlist 몇 개에 들어있는 track보다 상대적으로 playlist의 특성을 대표하기 어렵다고 볼 수 있는데 이를 수식에 적용한 것 같다.
다만 실제로 모델을 돌려보았을 때 $\beta \rightarrow 1$일수록 성능이 좋지 않았다.
4. Relevance $r_{ui}$
\[\scriptsize{ r_{ui} = \frac{1}{|\mathcal{T}(u)|} \sum_{j \in \mathcal{T}(u)} s_{ij} }\]track $j \in |\mathcal{T}(u)|$에 대해 앞에서 구한 similarity를 평균을 낸다.
이 값이 playlist $u$에 대한 track $i$의 relevance이다.
모든 track에 대한 relevance를 구하고 여기서 가장 높은 $m$개를 순서대로 구하면 된다.
song에 대한 모델에서는 $m = 100$, tag에 대한 모델에서는 $m = 10$이 된다.
논문은 track에 대해 사용을 했는데 여기서는 tag도 예측을 해야하므로 song과 tag 두 경우에 대해 동일하게 모델을 사용하였다.
Modeling
Input & Output
Neighbor 모델은 앞에서 설명한 방법으로 다음과 같은 예측을 한다.
- Song → Song
- Tag → Tag
여기서 Song이나 Tag가 비어있으면 비어있는 playlist에 대한 예측 결과는 모두 같을 것이다.
따라서 Song이나 Tag가 비어있지 않아야 예측의 의미가 있다.
Overview에서 구분한 각 case에 대한 ouput은 다음과 같다.
| case | input | output |
|---|---|---|
| case 1 | songs & tags | songs & tags |
| case 2 | songs only | songs only |
| case 3 | tags only | tags only |
| case 4 | no songs & no tags | none |
song이 있는 경우에는 song을 예측하고 tag가 있는 경우에는 tag를 예측한다.
예측하지 못한 경우에 대해서는 KNN을 사용한다.
Optimization
| hyperparameter | optimal value |
|---|---|
| $\alpha$ | 0.65 |
| $\beta$ | 0.0 |
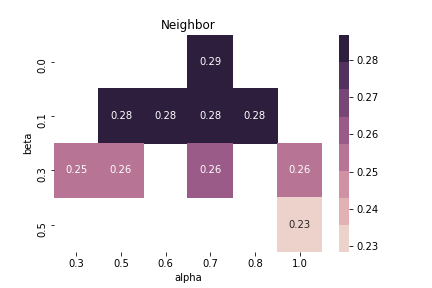
(heatmap에는 $\alpha = 0.65$인 결과 없음.)
Code
Neighbor.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
import numpy as np
import pandas as pd
from data_util import tag_id_meta
class Neighbor:
'''
Neighbor-based Collaborative Filtering
'''
__version__ = "Neighbor-3.0"
def __init__(self, pow_alpha, pow_beta, train=None, val=None, song_meta=None):
'''
pow_alpha, pow_beta : float (0<= pow_alpha, pow_beta <= 1)
train, val, song_meta : pandas.DataFrame
'''
### 1. data sets
self.train_id = train["id"].copy()
self.train_songs = train["songs"].copy()
self.train_tags = train["tags"].copy()
self.val_id = val["id"].copy()
self.val_songs = val["songs"].copy()
self.val_tags = val["tags"].copy()
self.val_updt_date = val["updt_date"].copy()
self.song_meta_issue_date = song_meta["issue_date"].copy().astype(np.int64)
### ?. parameters
self.pow_alpha = pow_alpha
self.pow_beta = pow_beta
self.__version__ = Neighbor.__version__
if not (0 <= self.pow_alpha <= 1):
raise ValueError('pow_alpha is out of [0,1].')
if not (0 <= self.pow_beta <= 1):
raise ValueError('pow_beta is out of [0,1].')
_, id_to_tag = tag_id_meta(train, val)
TOTAL_SONGS = song_meta.shape[0] # total number of songs
TOTAL_TAGS = len(id_to_tag) # total number of tags
TOTAL_PLAYLISTS = train.shape[0] # total number of playlists
### 2. data preprocessing
### 2.1 transform date format in val
for idx in self.val_id.index:
self.val_updt_date.at[idx] = int(''.join(self.val_updt_date[idx].split()[0].split('-')))
self.val_updt_date.astype(np.int64)
### 2.2 count frequency of songs in train and compute matrices
freq_songs = np.zeros(TOTAL_SONGS, dtype=np.int64)
for _songs in self.train_songs:
freq_songs[_songs] += 1
MAX_SONGS_FREQ = np.max(freq_songs)
self.freq_songs_powered_beta = np.power(freq_songs, self.pow_beta)
self.freq_songs_powered_another_beta = np.power(freq_songs, 1 - self.pow_beta)
### 2.3 count frequency of tags in train and compute matrices
freq_tags = np.zeros(TOTAL_TAGS, dtype=np.int64)
for _tags in self.train_tags:
freq_tags[_tags] += 1
MAX_TAGS_FREQ = np.max(freq_tags)
self.freq_tags_powered_beta = np.power(freq_tags, self.pow_beta)
self.freq_tags_powered_another_beta = np.power(freq_tags, 1 - self.pow_beta)
### constants
self.TOTAL_SONGS = TOTAL_SONGS
self.MAX_SONGS_FREQ = MAX_SONGS_FREQ
self.TOTAL_TAGS = TOTAL_TAGS
self.MAX_TAGS_FREQ = MAX_TAGS_FREQ
self.TOTAL_PLAYLISTS = TOTAL_PLAYLISTS
del train, val, song_meta
def predict(self):
'''
@returns : pandas.DataFrame; columns=['id', 'songs', 'tags']
'''
_range = range(self.val_id.size)
pred = []
all_songs = [set(songs) for songs in self.train_songs] # list of set
all_tags = [set(tags) for tags in self.train_tags ] # list of set
TOTAL_SONGS = self.TOTAL_SONGS # total number of songs
MAX_SONGS_FREQ = self.MAX_SONGS_FREQ # max frequency of songs for all playlists in train
TOTAL_TAGS = self.TOTAL_TAGS # total number of tags
MAX_TAGS_FREQ = self.MAX_TAGS_FREQ # max frequency of tags for all playlists in train
TOTAL_PLAYLISTS = self.TOTAL_PLAYLISTS # total number of playlists
for uth in _range:
playlist_songs = set(self.val_songs[uth])
playlist_tags = set(self.val_tags[uth])
playlist_updt_date = self.val_updt_date[uth] # type : np.int64
playlist_size_songs = len(playlist_songs)
playlist_size_tags = len(playlist_tags)
pred_songs = []
pred_tags = []
if playlist_size_songs == 0 and playlist_size_tags == 0:
pred.append({
"id" : int(self.val_id[uth]),
"songs" : [],
"tags" : []
})
continue
# predict songs
if playlist_size_songs != 0:
track_feature = {track_i : {} for track_i in range(TOTAL_SONGS)}
relevance = np.concatenate((np.arange(TOTAL_SONGS).reshape(TOTAL_SONGS, 1), np.zeros((TOTAL_SONGS, 1))), axis=1)
# feature vector
for vth, vplaylist in enumerate(all_songs):
intersect = len(playlist_songs & vplaylist)
weight = 1 / (pow(len(vplaylist), self.pow_alpha))
if intersect != 0:
for track_i in vplaylist:
track_feature[track_i][vth] = intersect * weight
# similarity and relevance
for track_i in range(TOTAL_SONGS):
feature_i = track_feature[track_i]
if (feature_i != {}) and (not track_i in playlist_songs):
contain_i = self.freq_songs_powered_beta[track_i]
sum_of_sim = 0
for track_j in playlist_songs:
feature_j = track_feature[track_j]
contain_j = self.freq_songs_powered_another_beta[track_j]
contain = contain_i * contain_j
if contain == 0:
contain = 1.0e-10
sum_of_sim += (self._inner_product_feature_vector(feature_i, feature_j) / contain)
relevance[track_i, 1] = (1 / playlist_size_songs) * sum_of_sim
# sort relevance
relevance = relevance[relevance[:, 1].argsort()][::-1]
sorted_songs = relevance[:, 0].astype(np.int64).tolist()
# check if issue_date of songs is earlier than updt_date of playlist
for track_i in sorted_songs:
if self.song_meta_issue_date[track_i] <= playlist_updt_date:
pred_songs.append(track_i)
if len(pred_songs) == 100:
break
# predict tags
if playlist_size_tags != 0:
track_feature = {track_i : {} for track_i in range(TOTAL_TAGS)}
relevance = np.concatenate((np.arange(TOTAL_TAGS).reshape(TOTAL_TAGS, 1), np.zeros((TOTAL_TAGS, 1))), axis=1)
# feature vector
for vth, vplaylist in enumerate(all_tags):
intersect = len(playlist_tags & vplaylist)
weight = 1 / (pow(len(vplaylist), self.pow_alpha))
if intersect != 0:
for track_i in vplaylist:
track_feature[track_i][vth] = intersect * weight
# similarity and relevance
for track_i in range(TOTAL_TAGS):
feature_i = track_feature[track_i]
if (feature_i != {}) and (not track_i in playlist_tags):
contain_i = self.freq_tags_powered_beta[track_i]
sum_of_sim = 0
for track_j in playlist_tags:
feature_j = track_feature[track_j]
contain_j = self.freq_tags_powered_another_beta[track_j]
contain = contain_i * contain_j
if contain == 0:
contain = 1.0e-10
sum_of_sim += (self._inner_product_feature_vector(feature_i, feature_j) / contain)
relevance[track_i, 1] = (1 / playlist_size_tags) * sum_of_sim
# select top 10
relevance = relevance[relevance[:, 1].argsort()][-10:][::-1]
pred_tags = relevance[:, 0].astype(np.int64).tolist()
pred.append({
"id" : int(self.val_id[uth]),
"songs" : pred_songs,
"tags" : pred_tags
})
return pd.DataFrame(pred)
def _inner_product_feature_vector(self, v1, v2):
'''
v1, v2 : dictionary(key=vplaylist_id, val=features)
'''
result = 0
for key, val in v1.items():
if key in v2:
result += (v1[key] * v2[key])
return result
if __name__=="__main__":
pass
from data_util.py import tag_id_meta
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import pandas as pd
def tag_id_meta(train, val):
'''
train, val : list of pandas.DataFrame
@returns : (dictionary, dictionary)
'''
tag_to_id = {}
id_to_tag = {}
data = [train, val]
tag_id = 0
for df in data:
for idx in df.index:
for tag in df["tags"][idx]:
if tag not in tag_to_id:
tag_to_id[tag] = tag_id
id_to_tag[tag_id] = tag
tag_id += 1
return tag_to_id, id_to_tag
train.json과 val.json에 있는 태그에 대한 두 개의 딕셔너리를 반환한다.
- tag_to_id : key = tag, value = id
- id_to_tag : key = id, value = tag
More Ideas
- Reweight & Reranking